
前言
这个文章是对论文 SmoothGrad: removing noise by adding noise 的个人解读和有关代码实现的讨论。SmoothGrad 论文发表于 2017 年。而 2016 年到 2017 年间是各种广为人知的可解释性方法爆发增长的两年,SmoothGrad 也是这一领域的著名论文之一。
作者使用了一个非常简单的方法解决了深度神经网络中存在大量噪声的问题。那就是通过添加噪声,从而通过平均的方法消除掉噪声的影响。尽管这个想法非常简单,但是却十分行之有效。所以,值得我们思考的是:
- 神经网络的梯度存在大量噪声的根本原因是什么?
- SmoothGrad 为什么会行之有效?
尽管目前可解释性人工智能(XAI)领域发展出了许多可解释性方法,但总的来说,XAI 研究是一个信任(Trust)或者说是归因(Attribution)的问题。之所以会需要XAI 技术,就是因为人在使用过程中不信任 AI,既不信任 AI 的学习能力,也不了解 AI 的运作机制。所以,才有了很多 XAI 方法来解析复杂 AI 模型背后的原理。但是,这又带来了一个问题,而且是一个非常关键的问题:XAI 方法的结果又真的可信吗? 这个问题显然是值得所有 XAI 领域研究者思考的,也是对现有的所有的 XAI 方法的一种重新思考。
摘要
在图像分类任务中,解释神经网络的一种方式就是解释每个像素对于最终决策的影响。这种策略的出发点就是类别分数对于输入图像的梯度。这个梯度可以被解释为“sensitivity map”(这里翻译为灵敏性图),并且有大量的可解释性方法是基于此的。SmoothGrad 的工作就是提出了一种帮助在视觉上锐化基于梯度的灵敏性图,并且讨论了一些经验。作者在 GitHub 上面开源了自己的代码。
1 背景介绍
解释复杂的机器学习模型,如深度神经网络,仍然是一个挑战。然而,了解这些模型的功能对于构建应用程序及其本身的问题都很重要。从医疗保健领域(Hughes 等人,2016;DoshiVelez 等人,2014;Lou 等人,2012)到教育领域(Kim 等人,2015),有许多领域的可解释性很重要。例如,(Lou et al.,2012)中的肺炎风险预测案例研究表明,更具可解释性的模型可以揭示复杂模型忽略的数据中重要但令人惊讶的模式。关于可解释模型的综述,请参见(Freitas,2014;Doshi Velez,2017)。
感兴趣的一个例子是图像分类系统。为分类决定找到一个“解释”可能会揭示这些系统的潜在机制,并有助于增强它们。例如,反卷积技术(deconvolution)帮助研究人员识别出未能学习任何有意义特征的神经元,这些知识被用于改进网络,如(Zeiler 和 Fergus,2014)所述。
反卷积(deconvolution)是一个很有趣的工作。真正的反卷积方法是在论文《Adaptive deconvolutional networks for mid and high level feature learning》中提出的,但这论文(Zeiler 和 Fergus,2014)可以说把反卷积发扬光大了。
理解图像分类系统决策的一种常见方法是找到对最终分类特别有影响的图像区域。(Bahrens 等人,2010;Zeiler 和 Fergus,2014;Springenberg 等人,2014;Zhou 等人,2016;Selvaraju 等人,2016年;Sundararajan 等人,2017;Zintgraf 等人,2016)。这些方法(不同地称为灵敏度图、显著性图或像素属性图;见第 2 节中的讨论)使用遮挡技术或带梯度的计算为单个像素分配“重要性”值,以反映其对最终分类的影响。
这里作者提到了一大堆的论文。其中(Bahrens 等人,2010)这篇论文指的是《How to Explain Individual Classification Decisions》这篇论文。于 2010 年发表于 JMLR 上。这个时候深度神经网络还没有登上大众舞台,所以作者其实解释的都是一些机器学习分类器,比如 SVM 等。(Zhou 等人,2016)这篇论文指的是《Learning deep features for discriminative localization》,于 2016 年发表于 CVPR 上,其中提出了著名的类激活视图(Class Activation Map,CAM)方法,其作者周博磊对于卷积神经网络的神经元原理研究非常深入,该方法也催生了一系列基于类激活视图的 XAI 方法和弱监督定位方法。(Selvaraju 等人,2016年)指的是论文《Grad-CAM: Why did you say that?》,但其实这个只是这篇论文作者发表的预印本,其正式版本《Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization》于 2017 年发表于 ICCV 上,是 CAM 技术路线上的里程碑式技术,其引用量已经快要破 2 万了(本文写作时已经到达 19992)。(Sundararajan 等人,2017)这篇论文题目为《Axiomatic attribution for deep networks》于 2017 年发表于 ICML 上,其中提出了 Integrated Gradients(IG)方法,开创了 XAI 解释方法的积分梯度流派。(Zintgraf 等人,2016)这篇论文指的是《A New Method to Visualize Deep Neural Networks》这篇论文,于 2016 年发表于 ICML Workshop中。
在实践中,这些技术似乎经常突出对人类有意义的区域,比如脸上的眼睛。同时,灵敏度图在视觉上往往很嘈杂,显示了一些在人眼看来是随机选择的像素。当然,我们无法先验地确定这种噪声是否反映了网络如何执行分类的基本事实,或者是由于更肤浅的因素造成的。不管怎样,这似乎是一个值得进一步研究的现象。
这个也对应了前言中提到的一个问题——这些噪声产生的原因
本文描述了一种非常简单的技术,SmoothGrad,在实践中可以减少视觉噪声,也可以与其他灵敏度图算法相结合。其核心思想是选取指定的图像,通过向图像添加噪声来对相似的图像进行采样,然后对每个采样图像的灵敏度图进行平均。我们还发现,在训练时添加噪声的常见正则化技术(Bishop,1995)对灵敏度图有额外的“去噪”效果。这两种技术(用噪声训练和用噪声推断)似乎具有相加效应;将它们一起执行会产生最佳结果。
作者提到的在训练集中添加噪声的方法,来自于其引用的论文(Bishop,1995),其题目为《Training with noise is equivalent to tikhonov regularization》。其贡献如题目所示。事实上,作为一种事后解释的方法去使用时,一般是无法对模型进行重新训练的,所以这只能算是作者的一种尝试和探索。
论文将 SmoothGrad 方法与几种基于梯度的灵敏度图方法进行了比较,并展示了其效果。我们提供了一个猜想,并有一些经验证据支持,解释为什么这项技术有效,以及为什么它可能更能反映网络是如何进行分类的。论文还讨论了增强这些灵敏度图可视化的几种方法。最后,论文还提供了用于生成本文中所有图像的代码,以及网站上每种比较方法的 200 多个示例.
作者的代码被集成到一个 Python 库里面了,可以在 TensorFlow 1.x ,TensorFlow 2.x 和 PyTorch 的环境下使用。但是这样可能不利于阅读和理解。链接可以见论文原文。
2 Gradients as sensitivity maps
考虑一个将图像分类为集合 中的一个类别的系统。给定一个输入图像 ,许多图像分类网络(Szegedy et al.,2016;LeCun et al.,1998)为每个类别 计算一个类别激活函数 ,并通过最高分数确定最终的分类类别 。即,
几位作者提出了一种在输入图像中定位“重要”像素的数学的准确的方法,例如 (Baehrens et al., 2010; Simonyan et al., 2013; Erhan et al., 2009)。如果函数 是分段可微的,对于任何图像 ,可以通过对输入 求导来构建一个灵敏度图 。特别地,可以定义,
(Simonyan et al., 2013) 这个工作首次提出了 Saliency Map 的概念,Gradient x Values 方法就是其首次提出的。
在这里 代表了 的导数(也就是梯度)。直观地来说, 表示对于类别 ,对 的每个像素进行微小的变化会对分类得分产生多大的影响。因此,往往希望得到 可以突出表示关键区域。
在实践中,一个标签的敏感度图似乎与该标签对应的区域呈正相关 (Baehrens 等人,2010年; Simonyan 等人,2013年)。然而,基于原始梯度的敏感度图通常在视觉上是嘈杂的,如图 1 所示。此外,正如这幅图所示,与人类认为有意义的区域的相关性充其量也仅是大致的。

图1 一个噪声敏感度图,基于图像分类网络中“gazelle”类别得分的梯度。较亮的像素表示具有较高绝对值的偏导数。详见第 3 节中的可视化细节。
作者在这里引入了两个假设:1. 标签对应的敏感度图和标签所指示的区域有关。以图1为例子,“gazelle”这个标签所指示的区域就是图片中羚羊所在的区域,所以对应的敏感度图在这一块的绝对值就偏大。2. 原始的敏感度图是充满噪声的。
2.1 Previous work on enhancing sensitivity maps
在原始梯度可视化中存在一些明显的噪声,有几种假设可以解释这种现象。当然,一种可能性是这些图是网络正在做的事情的真实描述。也许散布在图像上看似随机的某些像素对于网络做出决策是至关重要的。另一方面,使用原始梯度作为特征重要性表示可能并不是最佳选择。为了寻求对网络决策更好的解释,一些先前的研究提出了对梯度敏感度图基本技术的改进方法;我们在这里总结了几个关键的例子。
使用梯度作为衡量影响的指标时存在一个问题,即重要特征可能会使函数 “饱和”。换句话说,它可能在全局上产生强烈影响,但在局部上具有较小的导数。Layerwise Relevance Propagation (Bach et al., 2015)、DeepLift (Shrikumar et al., 2017) 以及最近的 Integrated Gradients (Sundararajan et al., 2017) 等多种方法尝试通过估计每个像素的全局重要性而不是局部敏感性来解决这个潜在问题。使用这些技术创建的地图通常被称为“显著性图”或“像素归因”图。
关于这个问题,可以参考论文 Axiomatic Attribution for Deep Networks 中的讨论。
另一种增强敏感度图的策略是改变或扩展反向传播算法本身,目的是强调对最终结果的正面影响。两个例子是“反卷积”(Zeiler&Fergus,2014)和“导向反向传播(Guided Back Propagation)”(Springenberg等,2014)技术,它们通过在反向传播计算中舍弃负值来修改 ReLU 函数的梯度。目的是执行一种“去卷积”操作,以更清晰地显示触发高层单元激活的特征。类似的想法还出现在(Selvaraju等,2016; Zhou等,2016)中,它们提出了多层级单元梯度的组合方式。
在接下来的内容中,我们将详细比较“原始(Vanilla)”梯度图与由积分梯度方法和引导反向传播方法创建的梯度图。关于术语的说明:尽管术语“敏感度图”、“显著性图”和“像素归因图”在不同的语境中被使用,但在本文中,将统称这些方法为“敏感度图”。
2.2 Smoothing noisy gradients
关于增强敏感度图的先前工作存在一个可能的解释,据我们所知,该解释在文献中尚未直接讨论:函数 的导数在小尺度上可能会出现剧烈波动。换句话说,灵敏度图中所见到的明显噪点可能是由局部导数的本质上无意义的局部变化所导致的。毕竟,考虑到常见的训练技术,我们没有理由期望导数变化平稳。实际上,所涉及的网络通常基于 ReLU 激活函数,因此 通常甚至不会是连续可微的。
图 2 显示了强烈波动的偏导数示例。这通过选取一个特定的图像 和一个图像像素 ,并以梯度向量的最大入口的一部分 的值进行绘制,,对应于图像空间中的一个短线段 ,其中 。我们将它表示为最大条目的分数,以验证波动的显著性。该段的长度足够小,以至于对于人类来说,初始图像 和最终图像 看起来是一样的。此外,路径上的每个图像都被模型正确分类。然而,关于红色、绿色和蓝色分量的偏导数却发生了显著变化。
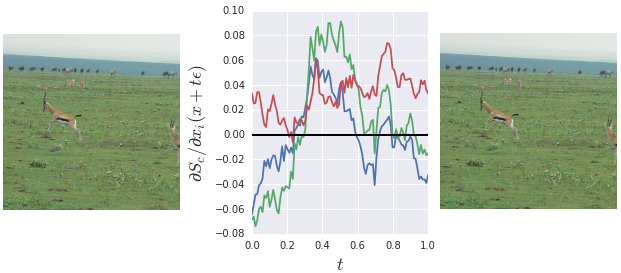
图2 RGB 像素值对梯度向量中最大分量的偏导数(作为分数表示)随着从基准图像 (中间图)缓慢移动到固定位置 (右图)逐渐变化。 是从 中随机抽取的一个样本。对于人类来说,最终图像 与原始图像 无法区分。
鉴于这些快速波动,任何给定点的 梯度将比梯度值的局部平均值表达得更不明显。这表明了一种改进敏感度图的新方法:不是直接基于梯度 来创建可视化,而是基于 用高斯核进行平滑。
直接在高维输入空间中计算这样一个局部平均是不可行的,但我们可以计算一个简单的随机近似。特别地,我们可以在输入 的邻域内取随机样本,并对得到的灵敏度图进行平均。在数学上,这意味着计算:
其中 为采样的数目, 代表标准差为 的高斯噪声。在这篇论文中我们把这种方法叫做 SmoothGrad。
作者的想法大致遵循这样的思路:发现原始梯度存在噪声 -> 用一个简单的 demo 说明该现象 -> 然后提出自己的解决方案。作者的方法其实非常简单,就是基于简单的高斯平滑的想法,但是后续的实验证明,该方法非常行之有效。
3 Experiments
为了评估 SMOOTHGRAD 技术,作者使用神经网络进行了一系列图像分类实验(Szegedy等,2016;TensorFlow,2017)。结果表明,估计的平滑梯度 比未平滑的梯度 具有更加视觉上连贯的敏感性图,所得的可视化结果更好地与有意义的特征对齐。
实验使用的模型为 Inception v3 在 ILSVRC-2013 数据集上进行训练,以及一个基于 TensorFlow tutorial 的卷积 MNIST 模型。
这些都是非常简单和常见的图像分类模型和数据集。
3.1 Visualization methods and techniques
敏感性图通常以热力图的形式进行可视化。找到从像素的通道值到特定颜色的正确映射方式,事实证明非常微妙,对可视化结果的印象有很大的影响。本节总结了一些可视化技术和在比较各种敏感性图工作的过程中所得到的经验教训。其中一些技术可能在选择敏感性图方法时无论如何都能普遍使用。
梯度的绝对值
敏感性图算法通常会产生带有符号的值。在将带符号的值转换为颜色时存在较大的歧义。一个关键选择是是否以不同方式表示正负值,或者仅可视化绝对值。将梯度值取绝对值与否的实用性取决于数据集的特征。例如,当感兴趣的对象在不同类别中具有相同的颜色时(例如,在 MNIST 数字数据集中,数字永远是白色(LeCun et al.,2010)),正梯度指示了向类别的正信号。另一方面,在 ImageNet 数据集中(Russakovsky et al.,2015),我们发现将梯度的绝对值取出能产生更清晰的图片。这种现象的一个可能解释是方向是依赖于上下文的:许多图像识别任务在颜色和照明变化下是不变的。例如,在对一个球进行分类时,在明亮的背景上,一个黑色的球会有负梯度,而在较暗的背景上,一个白色的球会有正梯度。
剔除离群值
我们观察到渐变存在着一些像素比平均值高得多的值。这并不是一个新的发现——这一特性在生成对人类不可辨别的对抗性样本时被利用了(Szegedy等,2013)。这些离群值有可能完全改变颜色尺度。将这些极值限制在相对高的值(我们发现 99 分位数足够)会导致地图更具视觉连贯性,就像 (Sundararajan等,2017) 中所示。如果没有这个后处理步骤,敏感性图可能几乎完全黑色化。
乘以输入的图像
一些技术通过将基于梯度的数值与实际的像素数值相乘来创建最终的敏感度图(Shrikumar等,2017; Sundararajan等,2017)。这种乘法往往会产生视觉上更简单和更锐利的图像,尽管目前尚不清楚其中有多少是归因于原始图像本身的锐利度。例如,输入中的黑/白边缘即使在基础的敏感度图中没有边缘,最终的可视化图像也可能出现边缘状的结构。
然而,这可能会导致不良的副作用。值为 0 的像素永远不会出现在敏感度图上。例如,如果我们将黑色编码为 0,那么在白色背景上正确预测黑球的分类器的图像将永远不会突出显示黑球。
另一方面,将梯度与输入图像相乘在我们将特征的重要性视为对总分数 的贡献时是有意义的。例如,在线性系统 中,将 视为 对最终得分 的贡献是有意义的。
3.2 噪声水平和采样的影响
SmoothGrad 有两个超参数:,表示噪声水平,也就是高斯扰动的标准差; 用来平均的样本数量。
Noise,
图 3 展示了噪声水平对于 ImageNet (Russakovsky等,2015) 中一些样例图片的影响。其中的第二列对应了标准的梯度(也就是 0% 噪声),后面全篇称其为“Vanilla”方法。鉴于对解释可视化结果的定量评估仍然是一个未解决的问题,因此主要关注定性评估。作者观察到,通过应用 10% 到 20% 的噪声似乎可以取得锐度和原始图像结构中的一个平衡。并且同样可以观察到,虽然这个噪音范围对 Inception 来说通常能得到良好的结果,但理想的噪音水平取决于输入。图 10 给了一个基于 MNIST 数据集的一个类似的例子。
Sample size,
在图 4 中,作者展示了采样数目 的影响。如预期所示,随着 的增大,估计的梯度会变得越来越平滑。根据实证研究结果,作者发现有递减回报现象——在 的情况下,可视化效果几乎没有明显变化。

图4 样本量对初始估计梯度的影响。每个图像添加了10%的噪声。
3.3 与基准方法的定性比较
由于没有真实标准来进行灵敏度图的定量评估,我们遵循之前的研究(Simonyan et al.,2013; Zeiler & Fergus,2014; Springenberg et al.,2014; Selvaraju et al.,2016; Sundararajan et al.,2017),并着重关注两个定性评估方面。
首先,我们检查视觉一致性(例如,亮点仅在感兴趣的物体上,而不是背景)。其次,我们进行区分性测试,在一张同时有猴子和勺子的图片中,我们期望关于猴子分类的解释集中在猴子而不是勺子上,反之亦然。
关于视觉连贯性,图 5 显示了我们的方法与三种基于梯度的方法之间的并排对比:Integrated Gradients(Sundararajan等,2017)、Guided BackProp(Springenberg等,2014)和 vanilla gradient。在我们检查的随机样本 200 幅图像中,我们发现 SMOOTHGRAD 相比于 Integrated Gradients 和 vanilla gradient 更一致地提供了更具视觉效果的映射。而 Guided BackProp 提供了最清晰的映射(图 5 的最后三行),但容易失败(图 5 的前三行),尤其是对于具有均匀背景的图像。相反,我们的观察结果是,当对象周围有均匀背景颜色时(图 5 的前三行),SmoothGrad 的影响最大。探索这种差异是一个有趣的研究领域。可能类别分数函数的平滑性可能与底层图像的空间统计学有关;噪声可能对不同纹理的敏感性产生差异性影响。
图 6 将我们的方法的区分度与其他方法进行了比较。每个图像至少有两个不同类别的对象,网络可能会识别出来。为了可视化地展示区分度,我们计算每个类别对应灵敏度图 和 ,并且缩放到 ,然后计算其差异 。我们然后把这些值绘制在一个发散色图上,其中 。对于这些图像,SmoothGrad 在质量上显示出了比其他方法更好的区分能力。目前还不能确定哪些属性影响给定方法的区分能力,例如,为什么 Guided BackProp 似乎显示出最弱的区分能力仍然是一个开放问题。
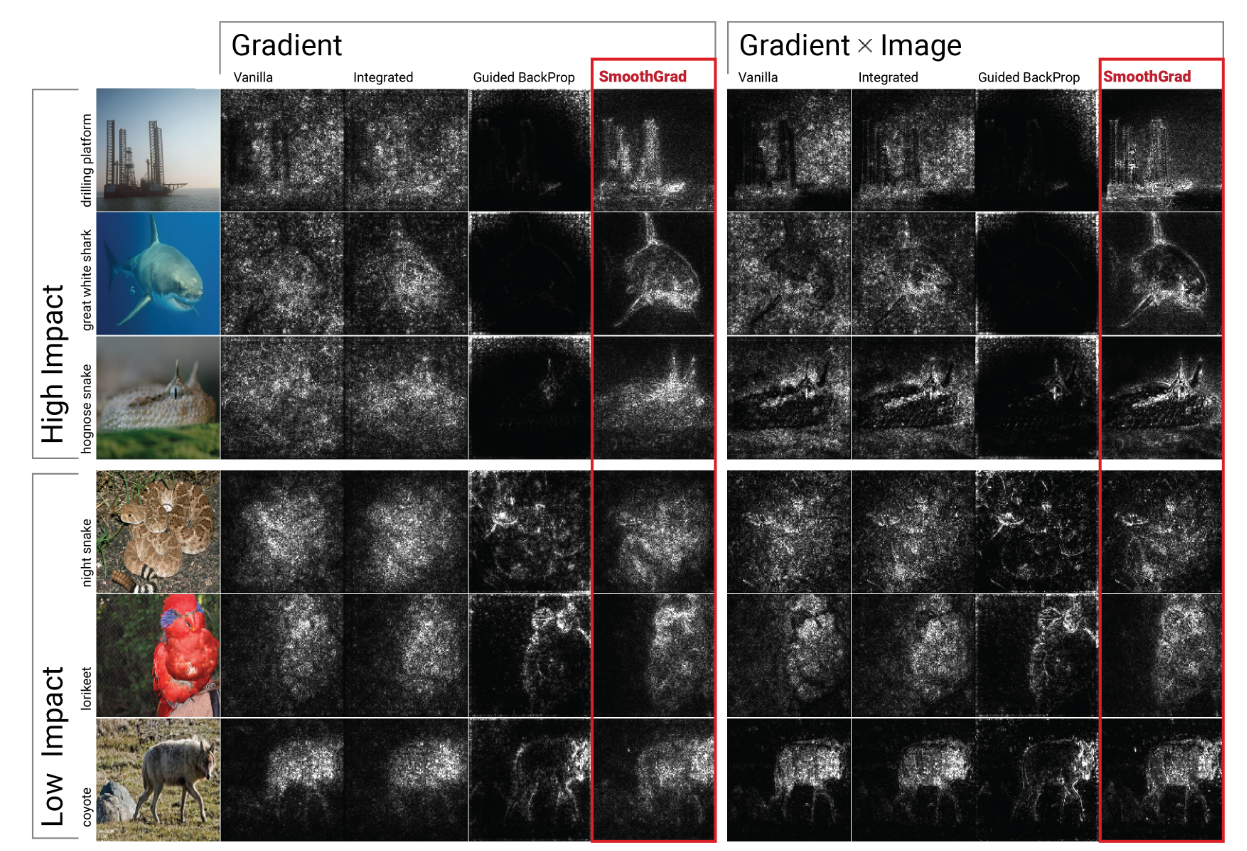
图5 定性评估不同方法。前三(后三)行显示了应用 SmoothGrad 对敏感性图质量具有高(低)影响的示例。
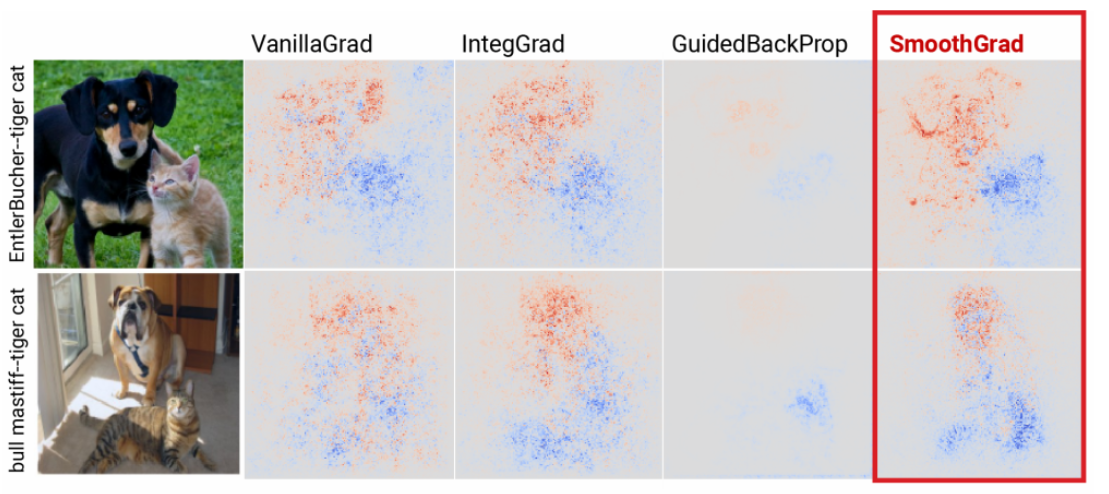
图6 不同方法的区分能力。对于每个图像,我们可视化不同的 ,其中 和 是第一类和第二类(即猫或狗)的 logits, 将梯度值归一化到 之间。使用发散的颜色映射 绘制数值。每种方法在列中表示。
3.4 将 SmoothGrad 与其他方法结合
可以将 SmoothGrad 想象为使用简单的过程对 Vanilla Gradient 方法进行平滑处理:对 n 个有噪音的图片的 Vanilla 敏感度图进行平均。有了这个想法,相同的平滑处理可以用来增强任何基于梯度的方法。图 7 显示了将 SmoothGrad 与 Integrated Gradients 和 Guided BackProp 结合使用的结果。我们观察到,这种增强改善了两种方法的敏感度图的视觉连贯性。
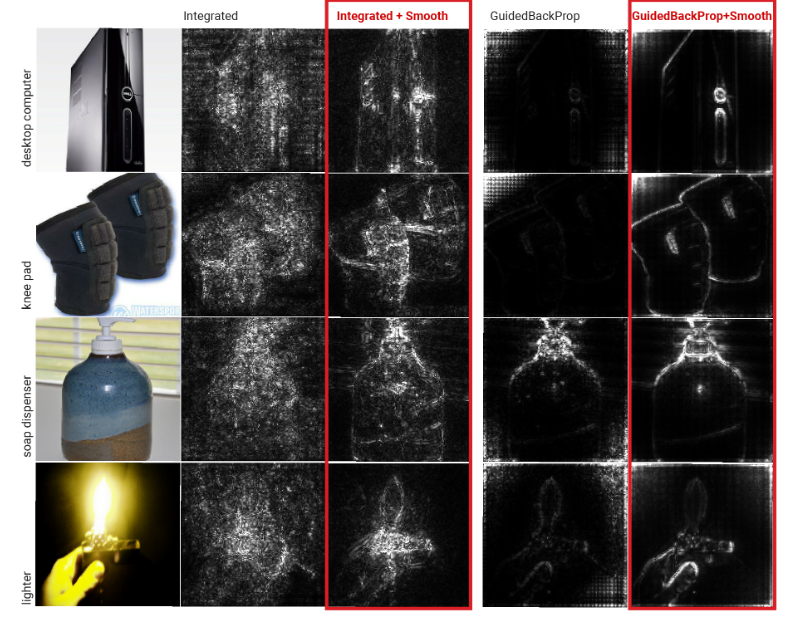
图7 将 SmoothGrad 与现有的基于梯度的方法一起使用:Integrated Gradients 和 Guided BackProp。
3.5 在训练过程中添加噪音
迄今讨论的 SmoothGrad 可以直接应用于分类网络。然而,在重视清晰度的情况下,自然会想到是否有一种类似的方法可以修改网络权重,使其敏感性图更加清晰。与 SMOOTHGRAD 在某种程度上平行的一个想法是在训练过程中向样本添加噪声的众所周知的正则化技术(Bishop,1995)。我们发现,这种方法也改善了敏感性图的清晰度。
图 8 和图 9 分别展示了在 MNIST 和 Inception 模型中,在训练时间和/或评估时间添加噪声的效果。有趣的是,在训练时间添加噪声似乎还能对敏感性图进行去噪。最后,这两种技术(训练时添加噪声和推断时添加噪声)似乎具有叠加效应;将它们同时执行能产生最具视觉连贯性的四种组合中的最佳敏感性图。
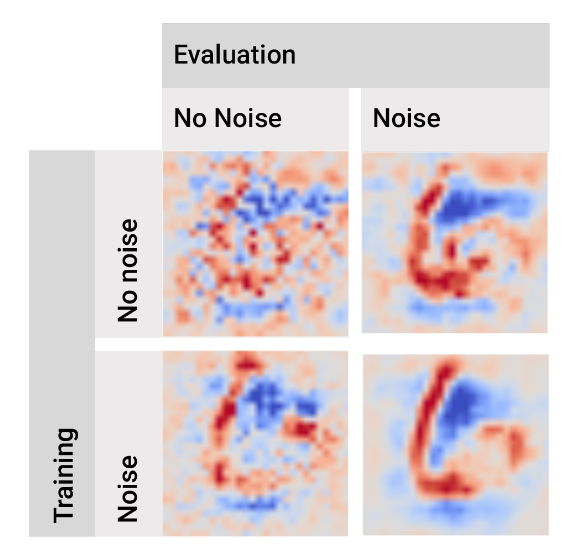
图8 在 MNIST 数据集上训练时添加噪声与评估时添加噪声的效果比较。
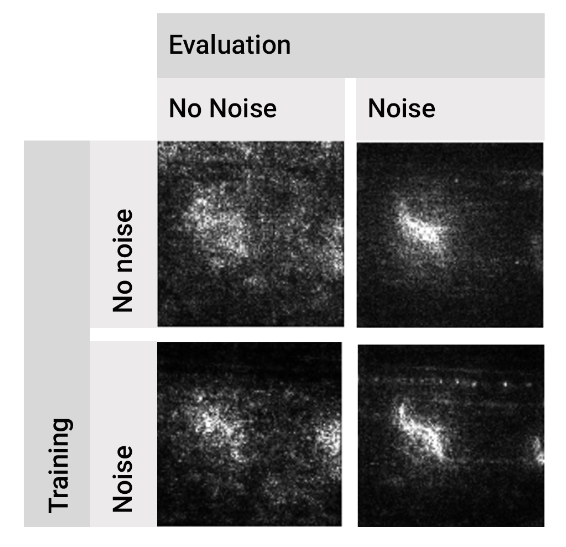
图9 在 Inception 模型的训练与评估过程中,添加噪声的效果
结论和未来工作
这里描述的实验表明,基于梯度的敏感性图可以通过两种平滑方式进行加强。首先,通过对给定图像进行许多小扰动形成的图像平均化,似乎有显著的平滑效果。其次,通过对数据进行加入随机噪声的扰动后的训练,可以进一步增强效果。
这些结果为未来的研究提供了几个方向。首先,虽然我们提供了一个关于嘈杂敏感性图是由噪声梯度引起的合理性论据,但寻找进一步的证据和理论论证来支持或否定这个假设是值得的。当然,SmoothGrad 的锐化效应可能存在其他原因,比如随机噪声对不同纹理的差异效应。
其次,除了噪声训练外,可能还有更直接的方法来创建具有更平滑类别得分函数的系统。例如,可以对偏导数的大小进行明确的惩罚来进行训练。为了创建更具空间连贯性的地图,可以对相邻像素的类别得分的偏导数之间的差异添加一个惩罚。此外,值得探究类别分数的几何结构,以理解为什么在具有大块近似恒定像素值的图像上看起来更平滑的效果更好。
进一步探索的一个领域是寻找用于比较敏感性图的更好度量标准。为了衡量空间一致性,可以使用现有的图像分割数据库,而我们已经在取得进展(Oh 等,2017年; Selvaraju 等,2016年)。系统性地测量可辨识性也可能非常有价值。最后,一个自然的问题是这里描述的去噪技术是否适用于其他网络架构和任务。
基于 PyTorch 的代码实现
基本思路
我们主要针对实验中对 ImageNet 数据集的可视化进行复现。所依赖的库如下:
numpymatplotlibtorchopencv-python (cv2)torchvision
加载所有的库
import numpy as np
import matplotlib.pyplot as plt
import torch.nn as nn
import torch
import torchvision
import cv2
图像分类模型的加载
weights = torchvision.models.VGG16_Weights.DEFAULT # 选择 VGG16 这个模型作为分类模型
model = torchvision.models.vgg16(weights=weights) # 如果下载很慢,可以提前下载好模型权重放在指定位置
目标图像的加载和可视化
img_path = "./data/imagenet_samples/dog.JPEG" # 换成想要可视化的图片的地址即可
img = plt.imread(img_path)
ax, fig = plt.subplots(1, 1, figsize=(10, 10))
fig.imshow(cv2.resize(img, (224, 224)))
fig.axis("off")
plt.show()
运行模型
img_input = torchvision.io.read_image(img_path)
img_input = weights.transforms(antialias=True)(img_input)
img_input = img_input.unsqueeze(0)
prediction = model(img_input).squeeze(0).softmax(0)
class_id = prediction.argmax().item()
score = prediction[class_id].item()
category_name = weights.meta["categories"][class_id]
print(f"{category_name}: {100 * score:.1f}%")
计算 Vanilla Gradient
x = img_input
x.requires_grad = True
y = model(x)
model.zero_grad()
x.grad = None
one_hot = torch.zeros(y.shape)
one_hot[:, class_id] = 1
y.backward(one_hot)
vanilla_grad = x.grad
可视化 Vanilla Gradient
def visulize_absscale(salience):
vmax = abs(np.percentile(salience, 99))
vmin = np.min(salience)
return np.clip((salience - vmin) / (vmax - vmin), 0, 1)
salience = vanilla_grad.detach().numpy()
salience = np.sum(salience, axis=1)
salience = salience[0]
salience = visulize_absscale(salience)
ax, fig = plt.subplots(1, 1, figsize=(10, 10))
fig.imshow(salience, cmap="jet")
fig.axis("off")
plt.show()
计算 SmoothGrad
n_samples = 50
bound_min = -2.1179039478302
bound_max = 2.640000104904175
sigma = 0.2 * (bound_max - bound_min)
x_grad = torch.zeros(size=[n_samples, *x.shape])
for i in range(n_samples):
x_noise = x.detach() + torch.randn(x.shape) * sigma
x_noise.requires_grad = True
y = model(x_noise)
y.backward(one_hot)
x_grad[i] = x_noise.grad
smooth_grad = x_grad.mean(dim=0)
可视化 SmoothGrad
salience = smooth_grad.detach().numpy()
salience = np.sum(salience, axis=1)
salience = salience[0]
salience = visulize_absscale(salience)
ax, fig = plt.subplots(1, 1, figsize=(10, 10))
fig.imshow(salience, cmap="jet")
fig.axis("off")
plt.show()